v3 · Apache 2.0
One AI agent. All your databases and code. Ask anything. Instant answers. No hallucinations.
Ask questions across your whole company. GraphJin finds the right data, runs the query, and shows the evidence.
3 relevant sources discoveredrelationships + churn filters valid3 optimized, policy-checked operationsEvidence checked · 3 systems · 3 operations
Meridian Robotics — renewal in 9 days, usage down 38%, two failed payments, and an unresolved escalation.
Deployed at scale
“I deployed GraphJin at a large Silicon Valley company, where it works across Snowflake, Postgres, and other databases spanning 5,000+ tables and 100 billion rows. It also connects to the company’s sales, marketing, and other SaaS APIs.”

See it work
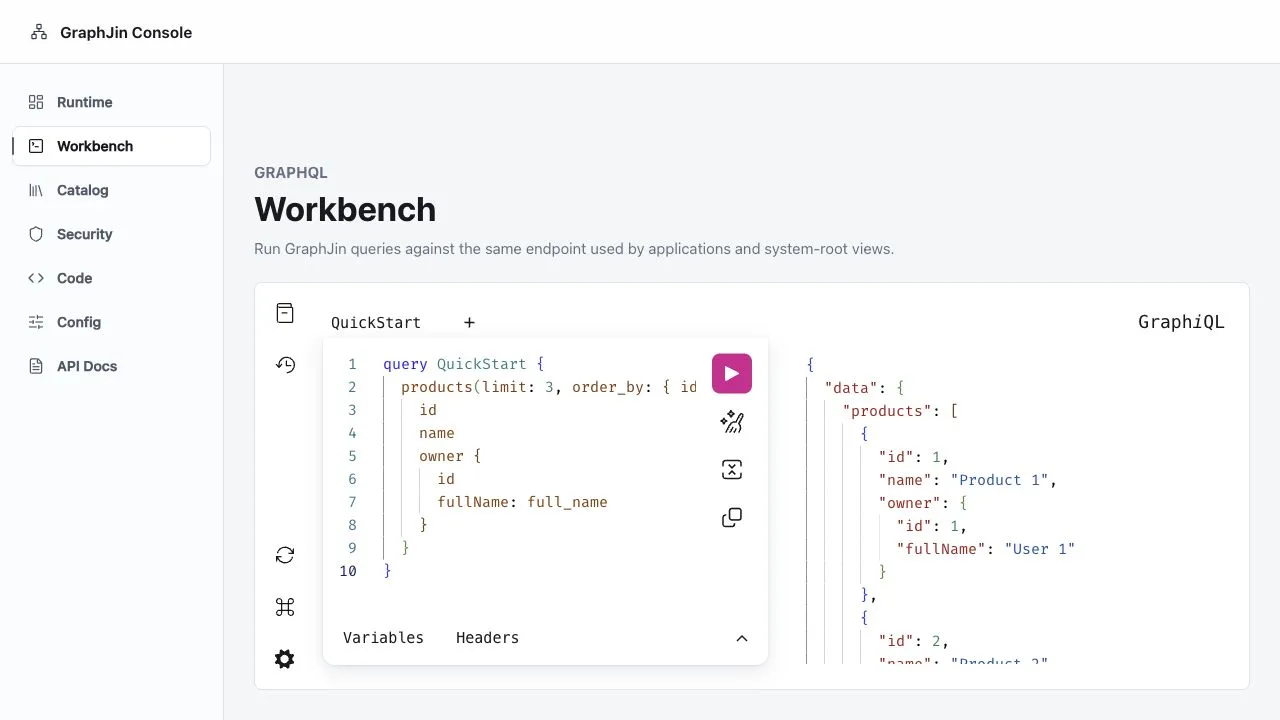
Ask in plain English. Get real data back.
Ask a question. Watch GraphJin discover the relevant shape, validate the request, compile the operation, and return the rows behind the answer.
discover -> customers · purchases · products (2 relationships)validate -> filters ok on customers, purchases · order_by total_spent{ customers { id full_name email purchases { quantity product { price } } } }one optimized query, no N+1, no resolvers
SELECT json_agg(__sj.json) AS customers
FROM customers AS c
LEFT JOIN LATERAL (
SELECT sum(p.quantity * pr.price) AS total_spent
FROM purchases p
JOIN products pr ON pr.id = p.product_id
WHERE p.customer_id = c.id
) __agg ON true
ORDER BY __agg.total_spent DESC NULLS LAST
LIMIT 5;Done
Based on the purchase data, here are the top customers ranked by total spend:
Antwan Friesen is the top customer with almost $1,000 in purchases, about 60% more than the runner-up.
How it works
Why this still works at 5,000 tables.
GraphJin’s reasoning-with-code agent discovers only the schemas and relationships it needs, then writes compact, model-friendly dynamic GraphQL. The compiler turns that into optimized, policy-checked operations—keeping context small enough for smaller models, permissions enforced, and every answer backed by evidence from what actually ran.
Bring Claude or Codex over MCP, or use the built-in agent.
Built-in Web UI
Your GraphJin setup, visible.
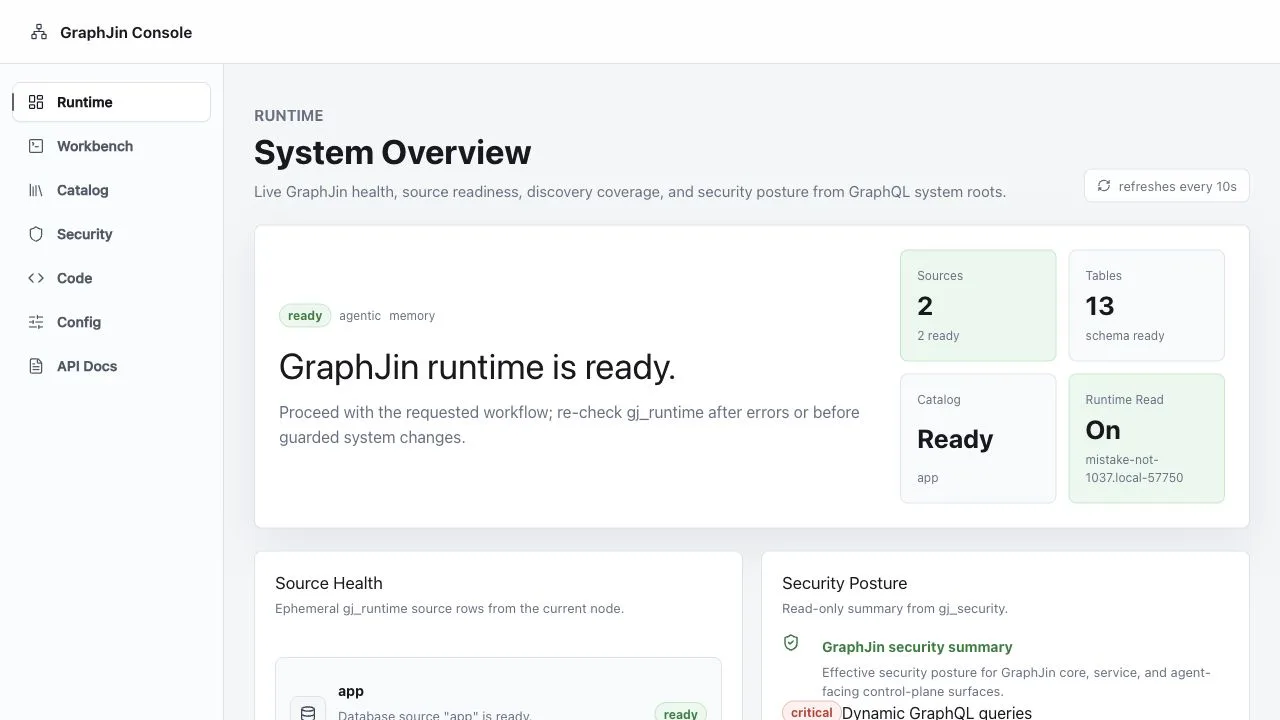
Every GraphJin server includes a first-party console. Ask the agent, inspect source health and discovery coverage, review security posture, run GraphQL, and follow tasks and watches—without deploying another service.
Know what is ready
Source health, schema discovery, and catalog status.
See the guardrails
Effective security posture and caller-specific capabilities.
Use the whole system
Agent, tasks, watches, Workbench, workflows, config, and API docs.
The problem
Your agent is only as good as what it can see.
$2.5 trillion goes into AI this year — and a capable model still enters your stack blind. It doesn't know your schema, your permissions, your saved queries, or where a field is written in code — so it works from memory and guesses.
A tool for every question
Worldwide AI spend in 2026 — yet teams still hand-write a brittle API or MCP tool for each thing an agent might ask. The surface never keeps up, and every new question is new glue code.
Guesses, not facts
The best model's success rate on real enterprise text-to-SQL — down from 91% on academic benchmarks. Without a map, agents invent joins, fake fields, and confuse API shape with database shape.
Too risky for production
Organizations that saw an AI-agent security incident in the past year. Handing an agent raw credentials means hoping it guesses right — so it stays read-only, shallow, or boxed out.
The fix isn't a smarter prompt. It's giving the agent the map — and the guardrails. And it isn't another raw connector: 43% of tested MCP servers shipped with command-injection flaws.4
Sources: 1. Gartner, Jan 2026 · 2. Spider 2.0, ICLR 2025 · 3. Gravitee State of AI Agent Security, 2026 · 4. Equixly, 2025
Only GraphJin
The only system that lets AI agents understand your whole organization.
Your systems
Postgres · Snowflake · MySQL · APIs · Files · Code
GraphJin
- Discover
- Connect
- Run
- Check
Agent answer
- Who is at risk
- Why
- What can happen next
Answer · data · evidence · actions
Bring your own agent
Set it up by talking to it.
One command connects Claude Code or Codex to GraphJin. After that you can stop editing config files. Ask for a new database connection, or a role that only ever sees its own customers’ rows, and GraphJin makes the change—but it tries the change against your real database first, so a bad idea fails in the chat instead of in production.
# One command. Nothing to start, no Docker, no config file.
claude mcp add graphjin -- graphjin mcp --demo
# Already running GraphJin? Point at it instead.
graphjin mcp add codex The first command hands your IDE a small sample database to play with, and keeps its own config out of reach. When you want GraphJin editing your project the way it does below, run graphjin serve new my-api and connect to that instead.
no databases yet · roles: anon, usertried it first -> staging connected · 34 tables found · no problemssaved to dev.yml · running now, no restartwhat it wrote to dev.yml
databases:
staging_pg:
type: postgres
host: ${PG_HOST}
roles:
- name: support
tables:
- name: customers
query:
columns: [id, name, plan, created_at]
filters: ["{ account_id: { eq: $account_id } }"]Tried against the real database before anything changed
Staging is connected. Support can read customers without the email column, and only their own account’s rows. I didn’t touch your login settings—those are off-limits to me, so the JWT secret is still yours to set.
It tries the change before making it
GraphJin connects to the database and reads the real schema to check your request would actually work. If it wouldn’t, nothing changes and you find out in the chat.
It cannot touch your secrets
Passwords, API keys and login settings are off-limits no matter who asks. A database you marked read-only stays read-only, even if the agent tries to change that.
Only while you are building
This works on your machine. On a live server the door is shut, and it cannot be opened by asking.
Built-in agent
Use GraphJin as the agent.
Send one plain-English instruction to one endpoint. GraphJin returns the answer, the data behind it, and evidence from what ran.
curl -sS localhost:8080/api/v1/agent \
-H 'content-type: application/json' \
-d '{"instruction": "What should we prioritize next?"}'{
"status": "answered",
"answer": "Start the Northstar run — priority 1, largest volume.",
"data": [
{ "product": "Northstar Blend 340g", "bags": 420 }
],
"evidence": {
"protocol": {
"executions": [{ "has_data": true }]
}
}
}Standing questions
Nothing happened. That was the problem.
Everywhere else on this page, you ask. Here you don’t. Leave a governed question running and GraphJin keeps answering it against live data—then speaks up when the answer changes, when something expected never arrives, or when it needs your permission to act.
no prompt · nobody asked
0 rows in 4h · absence window elapsed18 kg on hand · below safety buffer2 watches correlated → 1 signal1 conversation woken · 0 duplicates · action held
No shipment scan in four hours, and green-bean inventory is already under the safety buffer. Neither one is an alert on its own. Together, Tuesday’s roast stops by 14:00.
Written, attached, and not sent. The workflow stays paused until you approve this exact version.
You declare the window. A watch that sees zero rows in four hours fires exactly like one that sees a thousand, so silence stops vanishing between polls.
Routine events discard or roll into an unseen digest, and related watches correlate by exact ID into one signal. One conversation woke up, not four channels.
Alerts fail open. If AI triage is unavailable, GraphJin still sends the raw notification. Actions fail closed. A workflow never runs without the required approval.
Everything a standing question can do
Cursor-backed questions keep running across your systems.
“No shipment scan in four hours” becomes a first-class event.
Routine events drain into one useful, unseen summary.
Combine exact watch IDs without unsafe loops.
Hide an unseen event until later without acknowledging it.
Persist cursors and back off transient failures automatically.
Answers backed by evidence
The model made up an answer. The ledger caught it.
If no query ran, GraphJin will not let the model pretend that one did.
The model answers anyway
It names roast batches to hold.
No query ran
The execution ledger has no rows behind the claim.
GraphJin blocks it
The invented answer never reaches the caller.
{
"status": "blocked",
"refusal": {
"code": "saved_query_detail_required",
"blocked_action": "execute_saved_query",
"unblock": [
{
"tool": "query_catalog"
}
],
"retryable": true
}
}Try GraphJin
Your first answer is one command away.
Choose a demo, run the command, and ask a question. The data and agent are ready to go.
Coffee roastery
"Which roast batch should be held for quality — and why?"
graphjin serve --demo --path examples/coffee-roasterySaaS ops
"Which account is most at risk of churning?"
graphjin serve --demoCorrugated plant
"Which work orders should the corrugator run first?"
graphjin serve --demo --path examples/corrugated-plantPCB fab
"Which fab order should we release next — and what's the evidence?"
graphjin serve --demo --path examples/pcb-fabSupported systems
12+ database engines.
APIs, files, and code too.
Postgres, MySQL, Snowflake, Redshift, BigQuery, MongoDB, Oracle, SQL Server, SQLite, Cassandra and Keyspaces — plus remote HTTP APIs, object storage, filesystems, and CodeSQL source trees. Mix as many sources as your deployment needs behind one GraphQL and MCP surface.
 PostgreSQL
PostgreSQL
 MySQL
MySQL
 MariaDB
MariaDB
 MongoDB
MongoDB
 SQLite
SQLite
 SQL Server
SQL Server
 Oracle
Oracle
 CockroachDB
CockroachDB
 YugabyteDB
YugabyteDB
 Snowflake
Snowflake
 Redshift
BQ
BigQuery
C*
Cassandra / Keyspaces
Redshift
BQ
BigQuery
C*
Cassandra / Keyspaces
 AWS Aurora
AWS Aurora
 Cloud SQL
API
HTTP APIs
OBJ
S3 / GCS / Files
{ }
Code
Cloud SQL
API
HTTP APIs
OBJ
S3 / GCS / Files
{ }
CodeHow it works
One compiler. Any system. Any client.
Point GraphJin at databases, object storage, source trees, and remote APIs. It's a compiler, not a resolver framework: it learns the live shape, plans the work, and emits one optimized database operation — then enforces RBAC and serves AI assistants, REST clients, and federated routers from the same engine. No N+1, no resolver code, test-backed against real compiler paths.
The agent loop
Discover, check, validate, act.
A checked path from question to action.
Discover
gj_catalogCheck
gj_securityValidate
previewAct
governedSecurity model
Safer agents, not smaller agents.
One policy controls what agents can see, query, and change.
- RBAC and row filters
- Saved queries and allow-lists
- Read-only source boundaries
- Preview before change
Code intelligence
CodeSQL: query your code as well.
CodeSQL indexes your source tree into a read-only SQLite graph. Agents can ask where a column is used, which code references it, which symbol owns that reference, and what guarded change set would update it — all through the same GraphQL interface.
users.email used?query {
gj_code(where: {
name: { eq: "users.email" }
kind: { eq: "db_ref" }
}) {
path
symbol_name
}
}kind=filekind=symbolkind=db_refkind=docIn the box
A full backend, not just an agent gateway.
The same binary and config that govern the AI surface also run your realtime, files, remote APIs, auth, and federation — no extra services to operate.
Files as tables
Uploads stream to local disk, S3, R2, or GCS; each bucket is a queryable table you can join with the rest of your schema.
Remote APIs
Drop in an OpenAPI 3 spec and its operations become joinable, RBAC-aware fields with per-spec auth caching.
Realtime
Subscribe with the same GraphQL; cursor-based SSE and WebSocket streams resume after a drop, with polls batched into one statement.
Authentication
JWT and OIDC from Auth0, Firebase, Okta, or any JWKS — one auth pipeline across HTTP, WebSocket, SSE, and MCP.
Workflows
Discover approved workflows and run them through GraphQL, REST, MCP, or the CLI.
Caching
Response caching on Redis with an in-memory fallback and stale-while-revalidate.
One binary CLI
Dev server, database toolchain, device-code login, and MCP wiring. What runs in CI matches production.
Federation
Advanced: flip a flag and every keyed table becomes an Apollo Federation v2 subgraph.
Get started
Run it in two minutes.
Install GraphJin, add your model key, and start the demo.
# Install GraphJin
curl -fsSL https://graphjin.com/install.sh | bash
# Start the demo with your model key
OPENAI_API_KEY="your-key" graphjin serve --demo Open localhost:8083/agent and ask your first question.
Prefer your own IDE? In a second terminal run graphjin mcp add codex and ask Claude or Codex the same questions.